


Data is still king
Prototypes Are Free. Proprietary Data Is Priceless.
Tech has reached a tipping point. The time to market is quicker than ever, and I've experienced it firsthand. I built an open-source intelligence platform (OSINT) that aggregates signals from social media and news outlets, triangulates across sources, scores confidence, and surfaces emerging geopolitical events on a live map as they develop. It is a production-grade system, not a demo, and we are iterating on it publicly. It took one person and just a few days to build – not large cross-functional teams and months of development this kind of work would have required until recently.
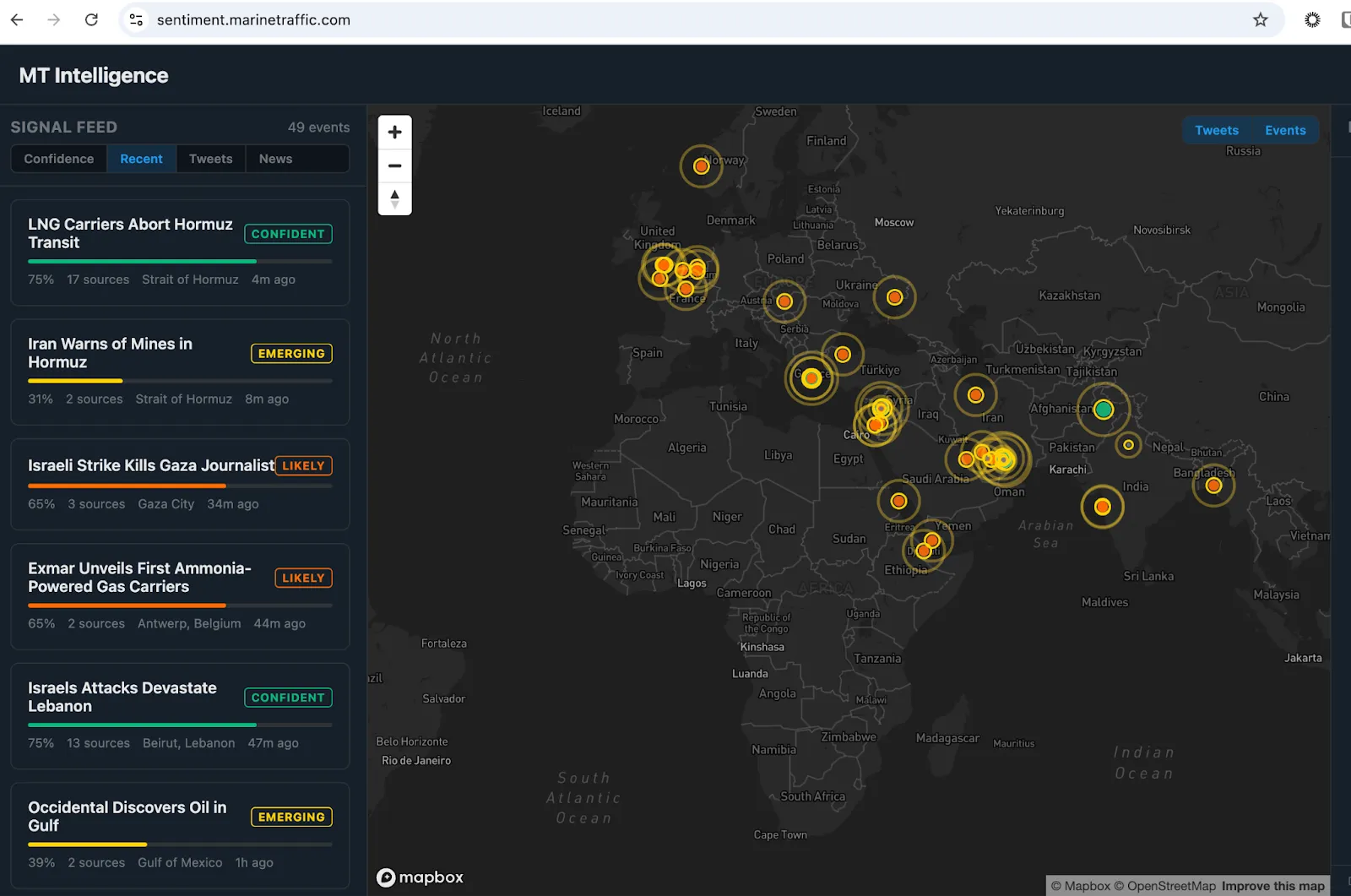
AI is compressing development timelines, and that part of the narrative is true. But what is also true is what AI cannot do for you. Yes, your tech is fast, but if your data is garbage, all you're doing is... bringing garbage to market faster.
“Dashboards of misinformation” proliferation problem
Across commodities, maritime, and energy we are seeing an explosion of dashboards and intelligence tools built on open-source data. They are often visually impressive, with maps showing vessel positions, charts with price overlays, and feeds that look authoritative at first glance. The people building them are smart and moving fast, and in many cases the interfaces are genuinely well-crafted.
The problem is not the design, but the foundation on which these tools are built. If “data is the new oil”, and that data is fundamentally flawed, these dashboards become like petrol engines running entirely on ethanol.
Open-source AIS data is inherently incomplete and retrospective. Commercially available news feeds are aggregated from public sources, which can lag by weeks or months, and in some cases longer. Case in point, data is being intentionally delayed or omitted on traffic in the Strait of Hormuz.
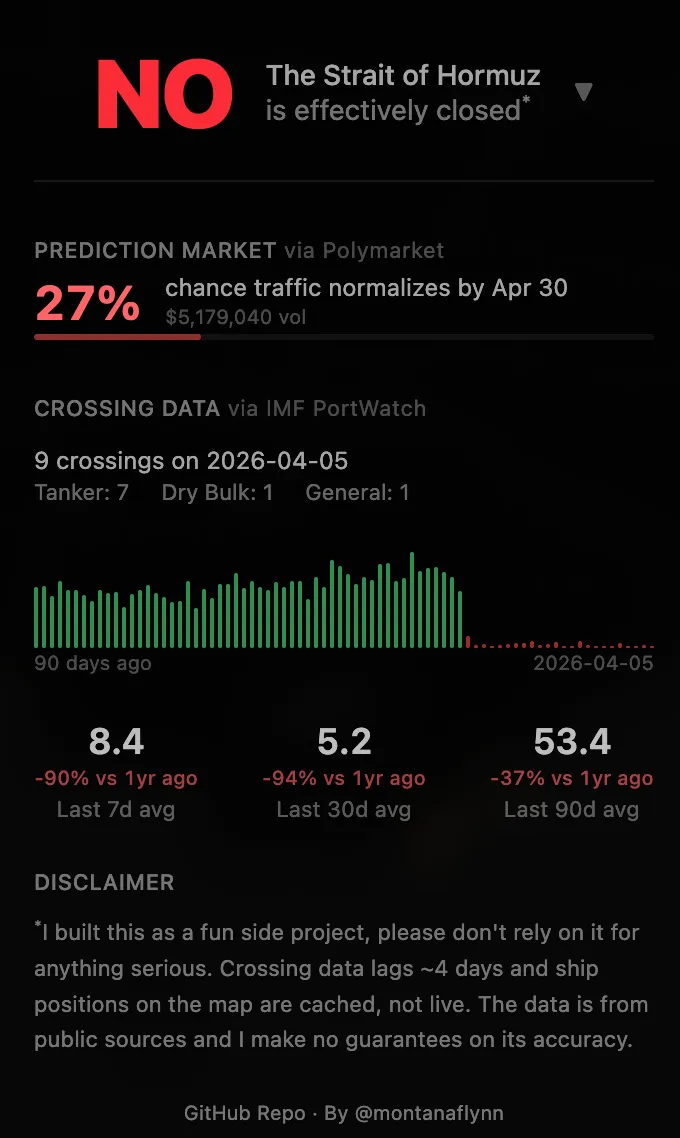
The above screenshot is an example of a dashboard built on freely available data including some from MarineTraffic.com. The creator of the dashboard acknowledges that the data lags and cautions against relying on the “fun side project” for anything serious. This is indeed a great fun project for developers and we applaud their ingenuity if not for the data scrapping. The issue is when businesses or individual investors begin conflating such projects with factual data that should be used in decisions that will inevitably cost resources.
More importantly, the domain expertise required to know what you are actually looking at takes years to develop. Understanding why a vessel going dark in a particular location means something fundamentally different from going dark somewhere else is not a question you can resolve with a better prompt. I have seen dashboards presenting sanctioned trade flows with confident visualisations that would fall apart under scrutiny from anyone with real market experience, and tools described as AI-powered that are, on closer inspection, thin wrappers around data sources with known quality issues. The surface holds up until someone who knows the market asks a question.
This is the gap that AI cannot close: not at the interface layer, not at the workflow layer, but at the level of the underlying data itself.
Proprietary AIS as a case study in advantage
To make this concrete, I used ChatGPT as the test case, and the contrast is stark.
AIS, the Automatic Identification System that vessels use to broadcast their position, is the foundational signal layer for the entire maritime intelligence industry. On the surface it sounds open: vessels transmit, receivers pick it up, and there are public aggregators. The reality of working with raw AIS data at scale is considerably messier. Vessels spoof their positions. Flags change. Transponders go dark, sometimes legitimately and sometimes not. Vessel identities are recycled, and the same physical ship can appear under different names, IMO numbers, and ownership structures across different timeframes.
Building something genuinely useful on top of AIS requires years of continuous investment: collection infrastructure across terrestrial and satellite receivers, entity resolution across millions of vessel histories, anomaly detection trained on known patterns of evasion, and human analyst verification at the edges where models are not confident enough to act alone. You also need the commercial intelligence layer, covering fixture data, cargo surveys, and port agent reports, to validate and enrich what the AIS signal alone cannot tell you. That stack, built over a decade, produces something qualitatively different from what any well-funded team can replicate in six months with modern tooling.
Here is what that difference looks like in practice:
Which Iranian-flagged vessels crossed the Strait of Hormuz laden with crude this week?
Without Kpler, ChatGPT can explain how Iranian-flagged VLCCs operate in the Gulf, that the Strait handles roughly 20% of global oil supply, and that vessel tracking is complicated by flag changes and transponder gaps. It cannot name the specific vessels that crossed this week, the direction they travelled, or what they were carrying.

With Kpler, the same question returns vessel names, IMO numbers, crossing dates, loading states, cargo types, and flag details refreshed every two hours. In the twelve days between March 24 and April 5 alone, ten Iranian-flagged vessels crossed laden with crude heading east: the Henna, Helm, Snow, Humanity, Derya, Tiyara, Hawk, Stream, Salina, and Halti, the majority of them VLCCs with deadweight tonnages above 290,000 tonnes. That is not analysis or inference. That is vessel-by-vessel ground truth, current as of this morning.
Which crude tankers are currently sitting as floating storage in the Middle East, and for how long?
Without Kpler, ChatGPT can explain that floating storage tends to build in contango markets and that the Persian Gulf is a common location, but it cannot tell you which vessels are doing this right now or for how long.
With Kpler MCP, 57 vessels are identified as of this week. The Tavaris Cassel has been floating off the UAE for 70 days, the Chloe off Iran since late January, and the TIMA at Changxing for 17 days. This is the physical oil market's hidden inventory, completely invisible to any news feed or general-purpose AI model.
Which crude vessels are waiting to discharge at Chinese ports right now?
Without Kpler, ChatGPT can speak to historical congestion patterns at Shandong and Zhoushan, but has no visibility into current wait times for named vessels.
With Kpler MCP, 14 vessels are in queue today across Huizhou, Zhoushan, Tianjin, Quanzhou, and Ningbo, with the TIMA at Changxing having waited 411 hours and two vessels at Huizhou exceeding 135 hours. Port congestion at this level is a leading indicator of refinery run rates, and it is the kind of signal that traders actively use to position.
The pattern across all three is consistent. Without proprietary data, ChatGPT provides structure, context, and historical framing that is genuinely useful but not actionable. With Kpler's data connected, the same AI produces answers that are relevant to commercial decisions being made today.
The temporal data dimension
There is a dimension to this that I think is underappreciated, particularly in commercial circles. Historical, curated data at scale is not just useful for answering questions about the past. It is the training substrate for building AI models that are genuinely domain-aware. A model trained on a decade of verified commodity flows, freight fixtures, refinery margins, and vessel behaviour patterns has a fundamentally different character to one trained on publicly available text. It can recognise patterns that have never been explicitly described anywhere, and it can flag anomalies because it has a true baseline to work from.
This is where the proprietary data advantage compounds over time. The argument is not simply that companies with better data answer today's questions more accurately, though they do. It is that those companies can build better models because they have been collecting and curating the right data for a long time, and that advantage widens as AI capability increases. Better AI applied to better data produces better outcomes than better AI applied to worse data, and the gap between those two trajectories grows rather than narrows.
What now?
If performance matters and your “engine” isn’t a toy, stop pouring sugar in the tank. Physical and financial traders and analysts cannot trust their books to memes and misinformation, and neither can the rest of the world. For those in commercial roles across commodities and maritime, look past the interface and ask where the data actually comes from, how fresh it is, and what happens to answer quality when market conditions are unusual, during a sanctions escalation, a supply shock, or a period of active vessel evasion. That is when the gap between genuine data coverage and the appearance of it becomes visible (and costly).
For those in product and technology roles, the implication is that dramatically cheaper software development does not eliminate competitive moats, it just changes where they live. Workflow and interface are increasingly commoditised, and that trend will continue. Proprietary, real-time, curated data with genuine domain depth is not commoditised, and AI makes it more valuable, not less.
The prototype explosion is real, and it is genuinely exciting. But what you build on top of matters more than it ever has.

See why the most successful traders and shipping experts use Kpler

Act smarter with Kpler AI






