How Kpler solves for missing data in European Power
Introduction - The problem
Clean and complete fundamental datasets are a critical building block to enable robust analysis and modeling of European power markets. When plant operators and TSOs fail to transmit data on load, generation, outages or other critical information, market participants face significant challenges in building a holistic picture of market dynamics. As a result, their capacity to forecast prices can be compromised.
Under the Transparency Regulation and associated ENTSO-E rules, TSOs are required to report data on unavailability of generation / production units (planned outages, forced outages) as part of “generation” datasets. However, on the ENTSO-E Transparency Platform, in the “Actual Generation per Production Type” view, many entries are tagged “n/e” (not existing / not available) at certain hours for certain production types / bidding zones leaving consumers of this data guessing at the values.
During a breakdown, fallback or default, zero reporting happens as well - which leaves market participants scrambling to fill these missing values. As an example, an incident occurred in 2024 where there was a known data outage incident affecting Germany: Amprion (a German TSO) reportedly could not provide solar generation data for certain hours, and temporarily published 0 values in lieu of the true data.
Without a reliable mechanism to detect and correct these gaps, market participants are stuck working with flawed inputs that can distort outcomes and delay action.
The solution
Kpler’s power market data & analytics solution, scrapes public sources covering most European power markets. While most data & analytics providers simply deliver the raw data with gaps, Kpler has developed proprietary machine learning algorithms which automatically identify and correct gaps in the data to ensure users have access to continuous time series with minimal publication delays.
Titled Platinum, this pipeline systematically identifies outliers and missing values in the time series we collect and uses machine learning approaches to generate best fit replacements. So far, more than 70,000 data points have been corrected.
The Platinum pipeline is underpinned by Kpler’s own forecasting models which it uses to impute data where missing or not reliable. Let’s take a look at how the feature was built, and a few examples, to understand how it is currently deployed to enhance datasets for Kpler Power customers.
How does it work?
The high level Platinum pipeline is captured in the diagram below:
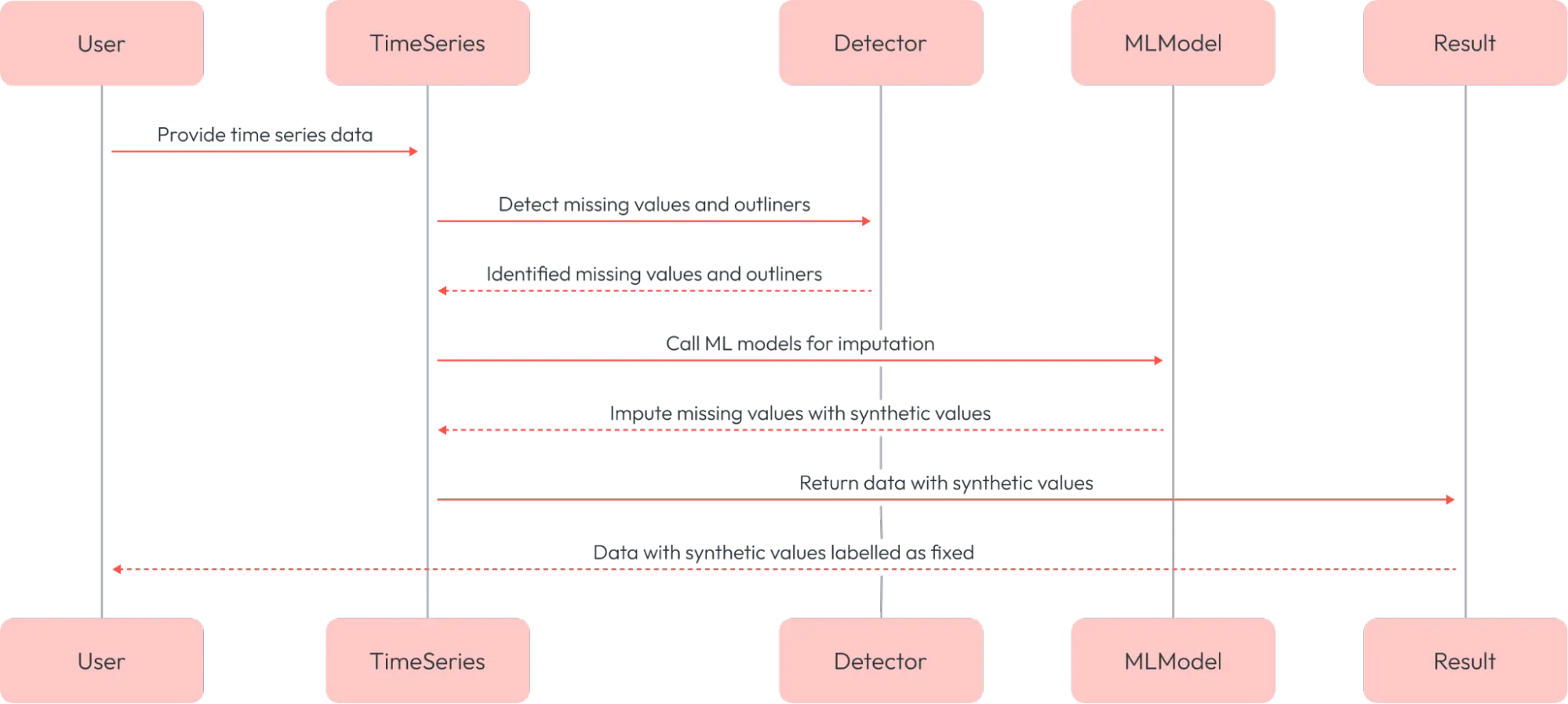
Detector pipeline
The detection step makes use of adtk pipelines. ADTK stands for Anomaly Detection Tool Kit — it’s an open-source Python library designed for unsupervised anomaly detection in time series data.
An ADTK pipeline usually refers to a sequence of steps one builds using ADTK’s components automatically. Our pipeline looks as per the diagram below:
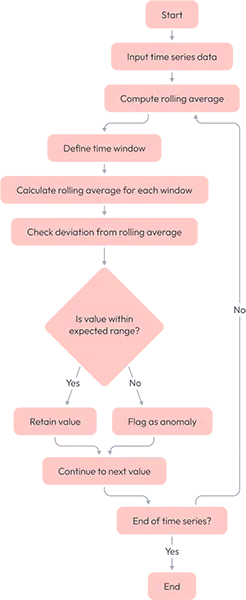
Machine learning models
Kpler uses machine learning models to predict each series that we correct, meaning we can forecast any value in the past that we consider unreliable and impute with an insample forecast. These ML models are trained every day and rely on exogenous factors, such as the weather, to predict power demand. They don’t learn on outliers so they are able to predict realistic synthetic values in a sanitised way for past outlier data points.
An example - Italian solar production
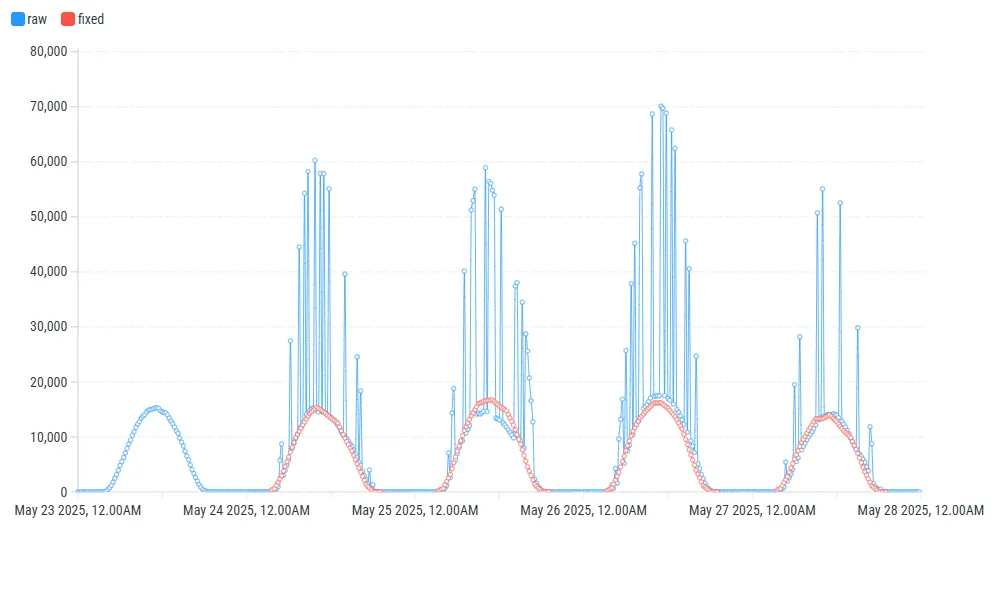
Since the beginning of 2025, Italian solar production reporting has been error-prone, as illustrated in the below graph. One can see that there are large spikes in the value for generation in the days following May 24. These do not represent actual load, rather they are erroneous figures from the reporting:
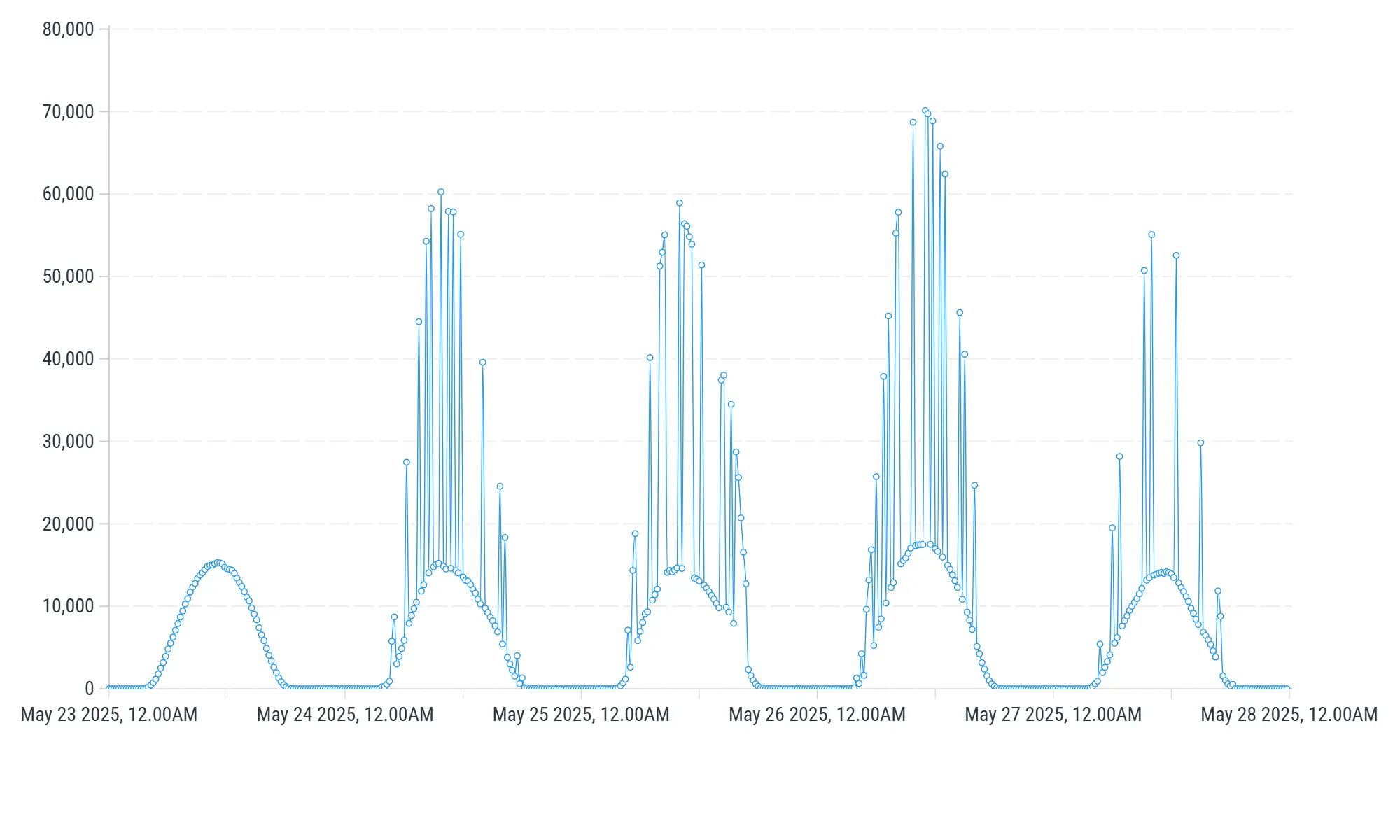
Based on our proprietary detection pipelines, Kpler can detect abnormal values, run our proprietary models to implement corrections in order to expose clean data through the API and the frontend for our customers. In the updated graph below, Kpler’s Platinum pipeline has actively found and addressed this issue, with the corrected values indicated in red, preventing poor data from being consumed by our customers.
In other instances, missing data is reported which leads to anomalies in the forecasting. Platinum also fixes this by applying estimates in real time to ensure no disruption to Kpler Power forecasts.
Below, we can see an example. The data for Bosnian power demand, as published by the Bosnian TSO and reported by ENTSO-E contained missing values from June & July 2024. As you can see indicated in red, the Platinum pipeline filled these gaps to make sure that users would not see any disruption in the data that they receive.
.webp)
Conclusion
By embedding anomaly detection and machine learning directly into its data pipeline, Kpler ensures that clients access continuous, high-integrity datasets optimised for analysis and forecasting. This not only safeguards the analytical process but also provides market participants with a consistent technical foundation for decision-making in fast-moving power markets. Kpler’s Platinum feature has been successful in correcting over 70,000 data points across European Power demand and generation in the last 10 years.
To learn more about how Kpler’s Power solution can help your business, speak with one of our specialists.

See why the most successful traders and shipping experts use Kpler

Unlock full power market analytics